 TULIP: Towards Unified Language-Image Pretraining
TULIP: Towards Unified Language-Image PretrainingDespite the success of contrastive image-text models like CLIP, they struggle with vision-centric tasks requiring high-fidelity understanding. We introduce TULIP, a novel model integrating generative data augmentation, enhanced contrastive learning, and reconstruction regularization to improve vision-language alignment. Our approach significantly outperforms existing models across multiple benchmarks, setting a new state-of-the-art in zero-shot classification and vision-language reasoning.
TULIP leverages generative data augmentation and enhanced contrastive learning techniques to improve fine-grained image understanding while maintaining strong language grounding. By integrating image-image and text-text contrastive objectives, alongside image/text reconstruction regularization, TULIP ensures robust vision-language alignment.
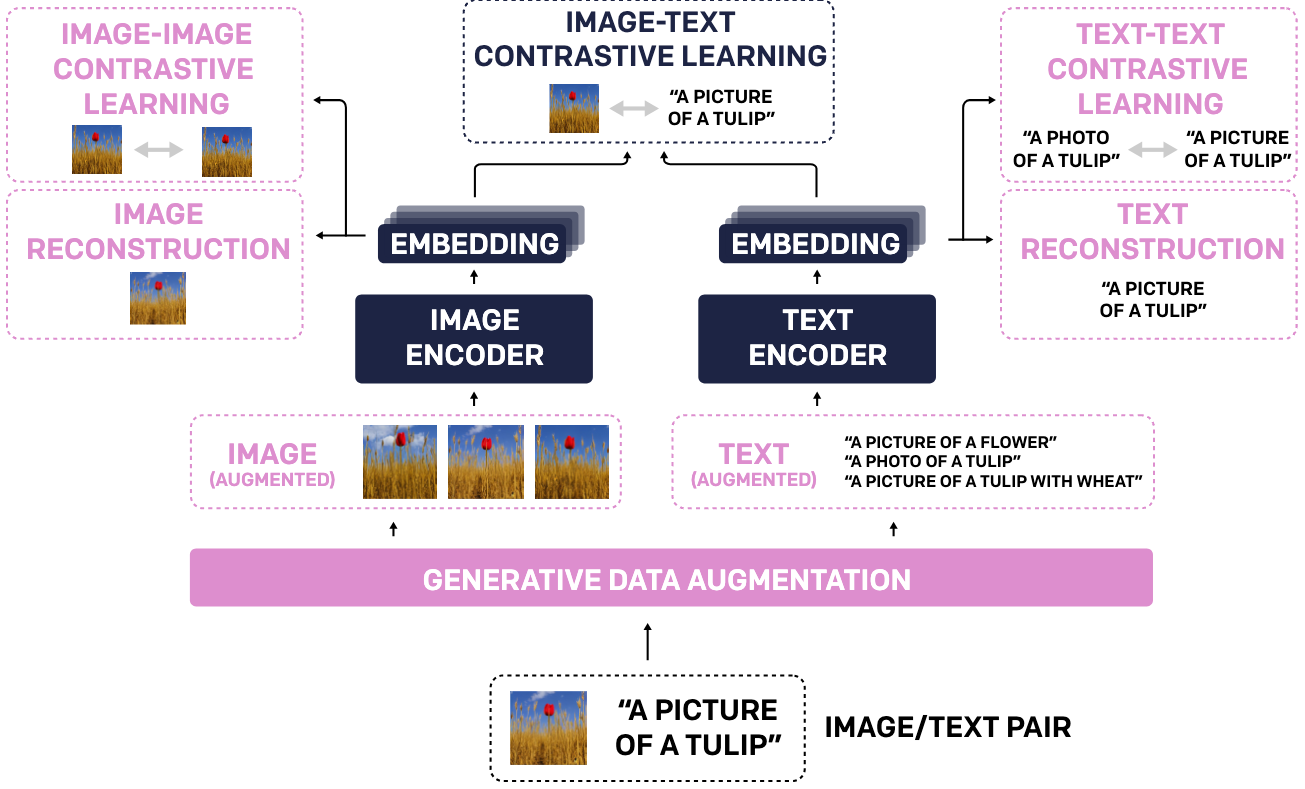
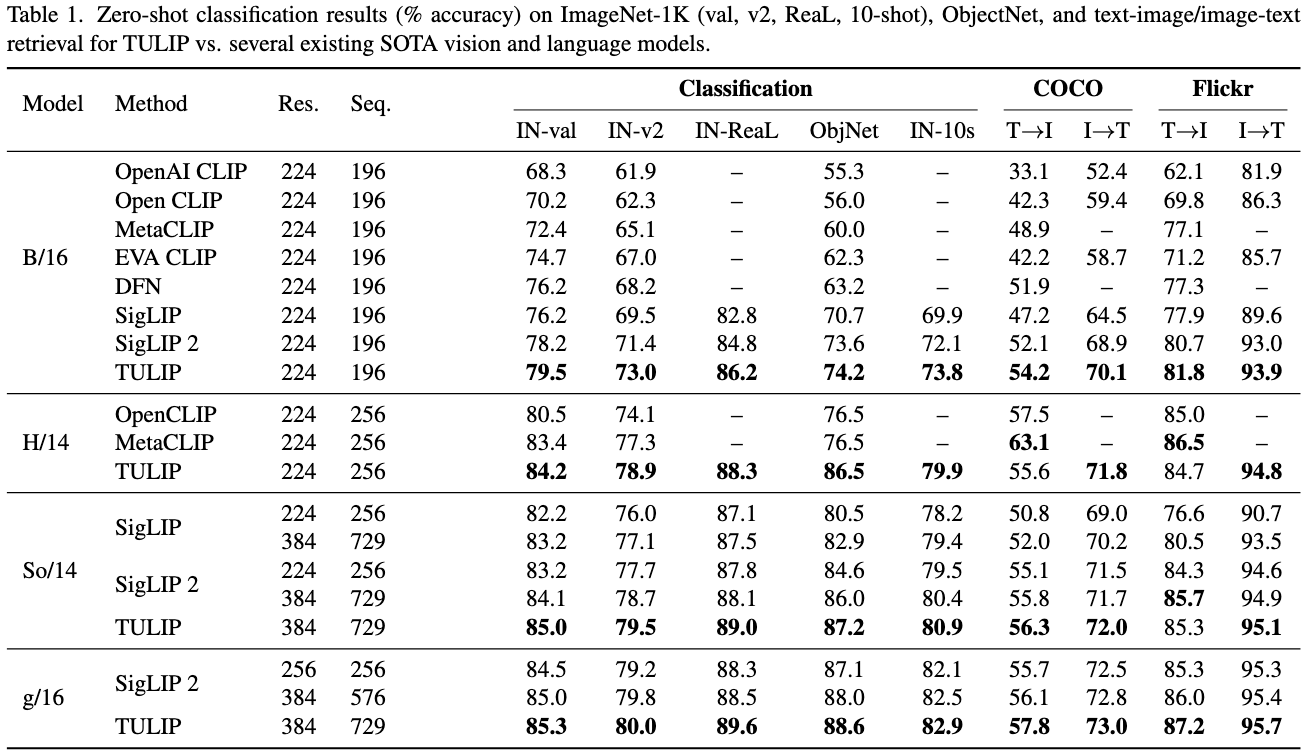
TULIP achieves state-of-the-art performance across multiple vision and vision-language benchmarks. It significantly improves zero-shot classification on ImageNet-1K, enhances fine-grained object recognition, and boosts multimodal reasoning scores. Compared to existing methods, TULIP shows up to a 3× improvement on MMVP and a 2× boost in fine-tuned vision tasks.
@misc{tang2025tulip,
title = {TULIP: Towards Unified Language-Image Pretraining},
author = {Zineng Tang and Long Lian and Seun Eisape and XuDong Wang and Roei Herzig and Adam Yala and Alane Suhr and Trevor Darrell and David M. Chan},
institution = {University of California, Berkeley},
year = {2025},
note = {Preprint},
}